Hinweis: Der Web-Crawler ist nur in den Tarifen Premium, Business und Enterprise verfügbar.
In diesem Artikel erfahren Sie mehr darüber, was ein Web-Crawler genau ist und wie er (technisch) funktioniert.
Neben dem Hinzufügen von Wissen durch Anleitungen, KI-Suchen oder den Dokumentenscanner möchten Sie möglicherweise auch Informationen von Ihrer Website in Ihren KI-Agenten integrieren. Genau das übernimmt der Web-Crawler. Er ruft zunächst alle URLs ab, die Sie crawlen möchten, und verarbeitet anschließend die Seiten, um deren Inhalte dem Wissen Ihres KI-Agenten hinzuzufügen. Dies vereinfacht die Pflege des KI-Agenten, da keine manuelle Datenerfassung erforderlich ist.
Sehen Sie sich dieses Video an:
1. Auf den Web-Crawler zugreifen
Öffnen Sie zunächst Ihren KI-Agenten und gehen Sie zu Quellen, um den Web-Crawler zu finden.

2. Ihre Website hinzufügen
Im Web-Crawler können Sie ganz einfach die URLs Ihrer Website hinzufügen und verwalten. Es gibt drei Möglichkeiten, URLs hinzuzufügen – diese lassen sich auch kombinieren:
- Gesamte Sitemap: Dies ist die empfohlene Methode, da sie die umfassendste Liste an URLs liefert. Erfahren Sie hier mehr darüber, wie Sie eine Sitemap erstellen können.
Fügen Sie die URL der Sitemap ohne '/' am Ende ein. Zum Beispiel: https://website.com/sitemap.xml – aber nicht: https://website.com/sitemap.xml/
- URLs über die Root-Domain abrufen: Dabei wird versucht, URLs über die gesamte Website hinweg zu finden.
- Einzelne URLs manuell hinzufügen: Diese Option eignet sich, wenn Sie nur Informationen von bestimmten Seiten Ihrer Website einfügen möchten – nicht jedoch von der gesamten Website.
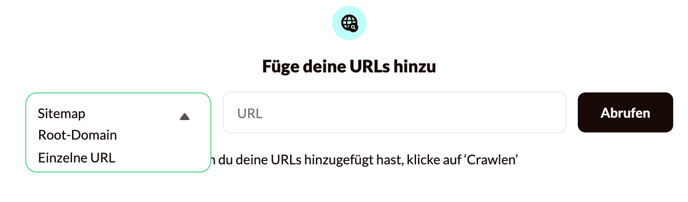
Nachdem Sie die URL in die Leiste eingefügt haben, klicken Sie auf Links abrufen. Der Web-Crawler zeigt die abgerufenen URLs in der Tabelle an. In dieser Tabelle wird auch angezeigt, wann die jeweilige URL hinzugefügt wurde. Abhängig von der Anzahl der URLs kann das Abrufen etwas Zeit in Anspruch nehmen.
Das Abrufen der URLs ist der erste Schritt. Sobald die URLs abgerufen wurden, können Sie für jede URL entscheiden, ob Sie:
-
URLs in das Crawling einbeziehen oder ausschließen (bestimmt, ob der Seiteninhalt dem Wissen des KI-Agenten hinzugefügt wird).
-
Die Verwendung der URL durch den KI-Agenten in Antworten aktivieren oder deaktivieren (bestimmt, ob der KI-Agent die URL in Gesprächen teilt).
Wenn Sie diese Entscheidungen getroffen haben, können Sie mit dem Crawling beginnen:
-
-
Wenn Ihre Website JavaScript enthält, ist es wichtig, den Schalter für „JavaScript rendern“ zu aktivieren. Beachten Sie, dass das Crawlen von JavaScript mehr Zeit in Anspruch nimmt, da zusätzlicher Aufwand nötig ist, um die Inhalte darzustellen.
-
Um alle einbezogenen URLs auf einmal zu crawlen, klicken Sie oben rechts auf Crawling starten.
-
Um nur ausgewählte URLs zu crawlen, wählen Sie die gewünschten URLs aus und klicken Sie im Menü auf Link crawlen.
-

Hinweis: Wenn das Crawlen einer Root-Domain oder Sitemap sehr schnell abgeschlossen ist (innerhalb weniger Sekunden), kann dies darauf hinweisen, dass nur ein kleiner Teil der Website gecrawlt wurde. Dies kann passieren, wenn die Website technisch schwer zugänglich oder nicht vollständig erreichbar ist. In solchen Fällen wenden Sie sich bitte an unser Support-Team.
Der Web-Crawler kann keine Informationen erfassen, die sich hinter Buttons oder Dropdown-Menüs verbergen. Solche Informationen müssen manuell in den Anleitungen des KI-Agenten hinzugefügt werden.
Crawl-Status
Die URLs in der Liste können verschiedene Status haben. Hier ein Überblick über die Bedeutungen:
| Status | Bedeutung |
|---|---|
| Gecrawlt | Die URL wurde dem Wissen des KI-Agenten hinzugefügt |
| Nicht gecrawlt | Die URL wurde noch nicht gecrawlt |
| In Warteschlange* | Die URL wartet darauf, gecrawlt zu werden |
| Ausgeschlossen | Die URL wurde vom Crawling ausgeschlossen |
Wie lange dauert das Crawling?
Das Crawlen einer Website kann bis zu 24 Stunden dauern – abhängig von der Struktur und Zugänglichkeit der Website. Während dieses Zeitraums versucht der Web-Crawler bis zu 50 Mal, URLs zu crawlen, die nicht sofort erreichbar sind. Währenddessen wird der Status der URL als In Warteschlange angezeigt. Wenn das Crawlen nach 24 Stunden nicht erfolgreich war, schlägt der Vorgang für diese URL fehl.
Manchmal scheint der Crawl-Status zwischen 90 % und 100 % zu stagnieren. Das bedeutet, dass der Web-Crawler noch versucht, eine kleine Anzahl verbleibender URLs zu erreichen. Diese können vorübergehend nicht verfügbar sein oder erfordern mehrere Versuche.
Sie müssen die Seite nicht geöffnet lassen, während das Crawling läuft. Der Vorgang wird automatisch fortgesetzt – auch wenn Sie eine andere Seite aufrufen oder sich von Watermelon abmelden.
Wenn Sie das Crawling nicht fortsetzen möchten, können Sie es manuell abbrechen. Das Wissen aller bis zu diesem Zeitpunkt erfolgreich gecrawlten URLs wurde bereits dem KI-Agenten hinzugefügt. Sie können also direkt mit den verfügbaren Informationen arbeiten.
Sobald das Crawling abgeschlossen oder abgebrochen ist, erhalten Sie eine E-Mail mit einer Zusammenfassung der Ergebnisse – einschließlich der Anzahl der URLs, die nicht erfolgreich gecrawlt werden konnten.
In diesem artikel finden Sie weitere Erklärungen dazu, warum eine URL möglicherweise nicht gecrawlt werden kann.
3. Crawlen abbrechen
Möchten Sie den Crawling-Vorgang stoppen, während er noch läuft? Sie können den Prozess manuell abbrechen:
- Klicken Sie während des Crawlings auf Abbrechen.
- Alle Anfragen, die sich bereits in der Warteschlange befinden, werden noch abgeschlossen. Danach stoppt der Prozess automatisch.
- Das Wissen aus allen bis zu diesem Zeitpunkt erfolgreich gecrawlten URLs bleibt erhalten und steht sofort in Ihrem AI Agent zur Verfügung.
Hinweis: Es ist nicht möglich festzustellen, von welchen IP-Adressen der Web Crawler auf Ihre Website zugreift.
4. URLs erneut crawlen
Wenn sich der Inhalt Ihrer Website ändert, können Sie das Wissen Ihres KI-Agenten ganz einfach aktualisieren, indem Sie auf Crawling starten (für alle einbezogenen URLs) oder Link crawlen (für ausgewählte URLs) klicken. So stellen Sie sicher, dass neue oder geänderte Inhalte in die Wissensdatenbank Ihres KI-Agenten integriert werden. Achten Sie beim erneuten Crawlen aller URLs auf Ihr Crawl-Limit.
5. Eine gecrawlte URL löschen
Um eine bestimmte URL aus dem Web-Crawler zu entfernen, klicken Sie auf die drei Punkte neben der URL und wählen Sie Löschen. Sie können auch die Mehrfachauswahl verwenden und im Menü auf Löschen klicken, um mehrere URLs gleichzeitig zu entfernen.
Hinweis: Das Löschen einer URL entfernt auch das gesamte Wissen, das der KI-Agent aus dieser URL erlangt hat.
6. Den KI-Agenten mit Website-Wissen testen
Sobald das Crawling abgeschlossen ist, können Sie Ihren KI-Agenten mit dem neu erworbenen Wissen im Interaktiven Tester testen. So sehen Sie, wie der KI-Agent die Inhalte der Website in Gesprächen nutzt.
Wenn Informationen auf Ihrer Website im Widerspruch zu manuell hinzugefügten Anleitungen in Ihrem KI-Agenten stehen, kann es zu einer Vermischung der Wissensquellen kommen, was zu uneinheitlichen Antworten führt
Sonstiges
-
Link kopieren: Verwenden Sie die Schaltfläche links neben der URL, um diese einfach zu kopieren. Dies ist nützlich, um die URL im Browser zu überprüfen und zu entscheiden, ob sie in das Wissen des KI-Agenten aufgenommen werden soll.

-
Lange URLs anzeigen: Wenn Sie mit der Maus über eine lange URL fahren, wird die vollständige URL angezeigt
BRAUCHEN SIE HILFE?
Wenn die Ergebnisse des Web-Crawlers nicht wie erwartet ausfallen, kontaktieren Sie uns unter support@watermelon.ai. Unser Support-Team hilft Ihnen gerne weiter!